
God Bless This Lousy Apartment
This was inscribed on a decorative plate that I found in a thrift shop in the back roads of northern Virginia. It was $5 dollars, so, naturally, I bought it. As soon as I got home to Raleigh I decided to prominently display this treasure for all to see – including my wife… Ever since, I have not lived a day without hearing how we need to move into a house. Decisions always seem worst in retrospect, don’t they?
But this did get me thinking – could I build a simple prediction model that would get me within the price for a given house in the Raleigh area based on easily accessible information (acreage, style, etc.). The answer, kind of… Who knew that housing prices were so complex?
Sampling
Getting the data was the meat of my journey. Thankfully, Wake County saves the taxed value of properties with some information about their construction and size on their early 2000’s website – http://services.wakegov.com/realestate/. My saving grace was the multitude of search options a person could use to search property and tax information.

Namely, I could search by a Real Estate ID. There are roughly 400,000 households in the Raleigh area. I did not want to pull all of the data, since my cheap Lenovo Yoga laptop from Walmart could not handle this load. Instead, I decided to pull a random sample of 1% (4,000) of records from this site.
 Here is the portion of my code used to do so. I created an empty set to house the ids, so building information would only be pulled once for a given ID. Then, I used a random number generator to pull one number, assign that to the ID, format it (so it would work in a url – we will see this later), and then pull the information on this ID if my computer had not already done so.
Here is the portion of my code used to do so. I created an empty set to house the ids, so building information would only be pulled once for a given ID. Then, I used a random number generator to pull one number, assign that to the ID, format it (so it would work in a url – we will see this later), and then pull the information on this ID if my computer had not already done so.
Scraping
Building a scraper will make you feel 200% cooler than you actually are – I highly recommend it. It’s even easier in the advent of tools that R-developers post online. I used the SelectorGadget by Hadley Wickham to get the source code for the information I wanted to pull from the government website.

The information I needed was on two different pages on this site. By subbing every randomly drawn ID into the base URLs, I could pull this information. Then, thanks to the SelectorGadget, I could pull what I wanted to be pulled (look at accountscrape =). The rest of the code pulls and formats the html information into usable data for me. Now, the loop continues for about 200 more lines: working through errors I encountered (who knew this website would have so many errors?) and building the data-frame for my sample. Ultimately, for every building in my sample, I pulled: Real Estate ID, Building Type, Units, Heated Area, Story Height, Style, Basement, Exterior, Heating, Air Conditioning, Plumbing, Year Built, Add Ons, Remodel Year, Fireplaces, Fire District, Land class, Zoning, Acreage, and Total Value. After much cleaning, I could finally build some models.
Model Building
I ended up building three different models by minimizing AIC, looking at the value of information, and using intuition. To test the utility of these models, I pulled 90 more housing IDs from the Wake County site as a testing set and predicted their housing prices using the models to compare against their government assessed value.
Model 1: `Total Value Assessed` ~ `Heated Area` + `Story Height` + Style + Basement + Exterior + Heating + `Air Cond` + Plumbing + `Year Blt` + Fireplace + Acreage
The adjusted R^2 for my first model was 0.72. This means that 72% of the variance in the value assessed to a home was explained by the variables included in this model. This isn’t too shabby, considering the complexity of homes and pricing – especially since specific location data was excluded. Below is a histogram of the distribution of the counts of houses that fall into different error (predicted housing value – assessed housing value) bins.

On average, this model under predicted by $18.7K. But, that is the funny thing about statistics – direction can effect the magnitude as it relates to averages. When we look at the average absolute difference between a prediction and the value assessed we see a difference of $73.6K. This is the difference between a 8.6% average error in prediction and a 22.7% average error. However, looking at the actual distribution gives us a better idea of what is going on. The model tends to do better at predicting than it does not (~50% of the time), but the length of the the tails could lead you to severely over pay for a house. So, at an individual housing price level this model may not be the best… But, in the unlikely case that you are looking at 100 to 1,000 homes, and you want to purchase them all at one time from one person, this model might serve you well…
Model 2: `Total Value Assessed` ~ (`Heated Area` + `Story Height` + Style + Basement + Exterior + Heating + `Air Cond` + Plumbing + `Year Blt` + Fireplace + Acreage)^2
Introducing two-way interactions among all the variables in our previous model increases the accountability for variance to 0.85 (adjusted R^2). So, how did it perform?
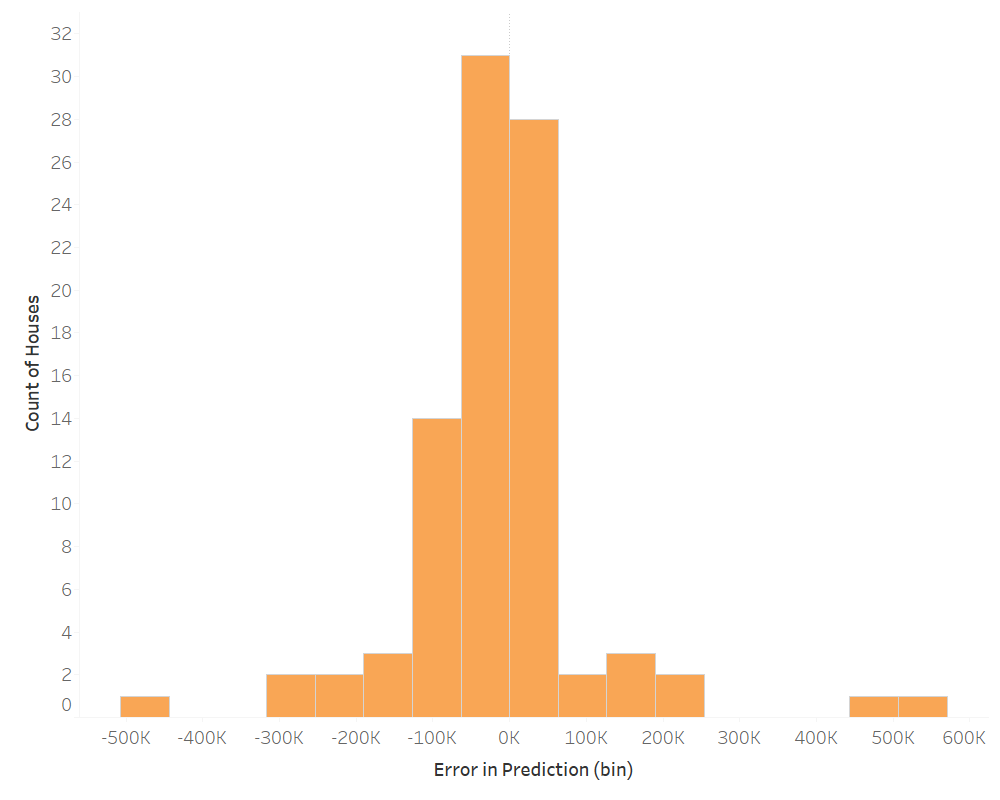
This model is infinity more complex due to the number of variables and the relationship between factors and factors or factors and continuous variables. We see an increase in the count of houses in the middle of the distribution, which means it is more accurate on average than the first model. But, the tails also become more extreme in their difference. On average, this model under predicted by $13.8K; this is an improvement on our original model. But, the average absolute difference between prediction and the value assessed is actually $74.7K.
Model 3: `Total Value Assessed` ~ `Heated Area` + Acreage + `Year Blt`
Our other models have been relatively convoluted. I decided to pick out three variables that I thought would influence price to see how it predicted. Here are the results.
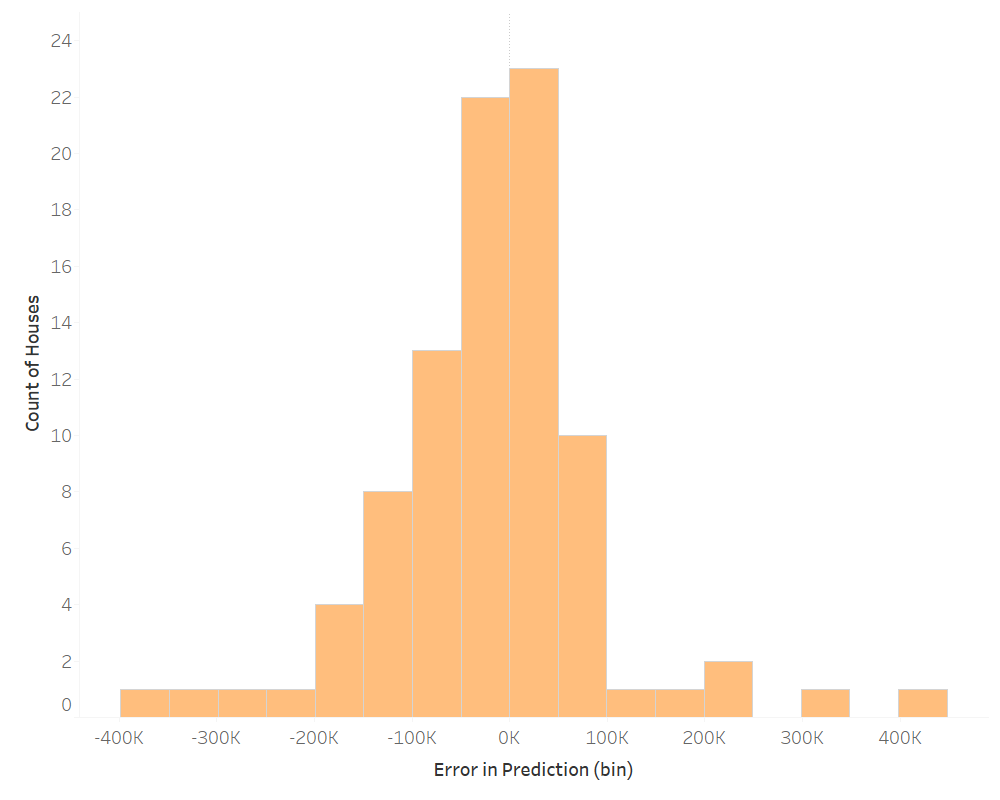
In this case, the adjusted R^2 was 0.69 – not far off from our first model. On average, this model under predicted by $19.7K. The absolute average was $77.4K. The distribution was similar to our first model. Not too bad for a model with only three variables.
Conclusion
So, when we inevitably go house shopping will I use any of these models? Probably not, but some interesting information can still be derived.
- Are you a gambler? Then a two-way interaction model might be for right you. You increase your odds of accuracy, but you also increase the magnitude of error if the model is inaccurate.
- Are you risk adverse? Then go simple, and spread your potential for loss across different scenarios. But, who doesn’t like a little excitement?
- Are you looking for a house? Then trust your realtor.
I believe that location, location, location, is a large determinant for the price of a house. Integrating this data would greatly increase the predictive properties of my models. Housing prices are also largely dictated by the market – supply and demand, interest rates, and economic growth. This, in addition to the data in my models, would greatly improve their predictability. But, for now, trust your realtor. They are the experts.
Enjoy this post? Take a look at past posts:
Michael Jordan vs Lebron James
NYC: Where to go for a night out?
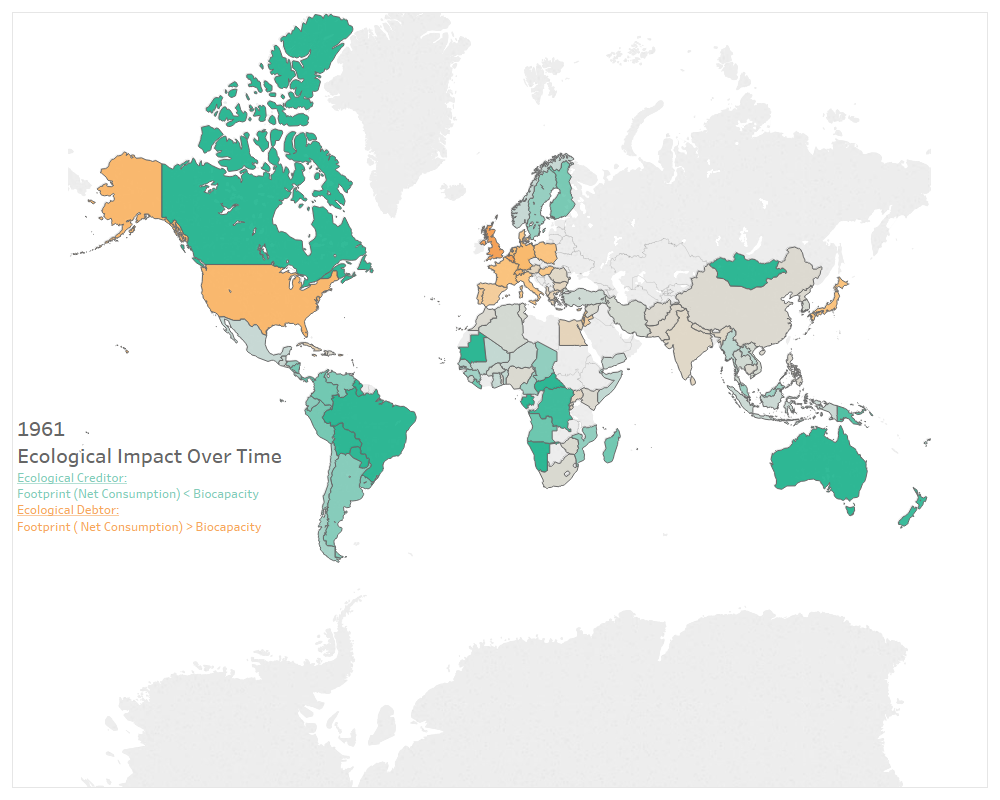
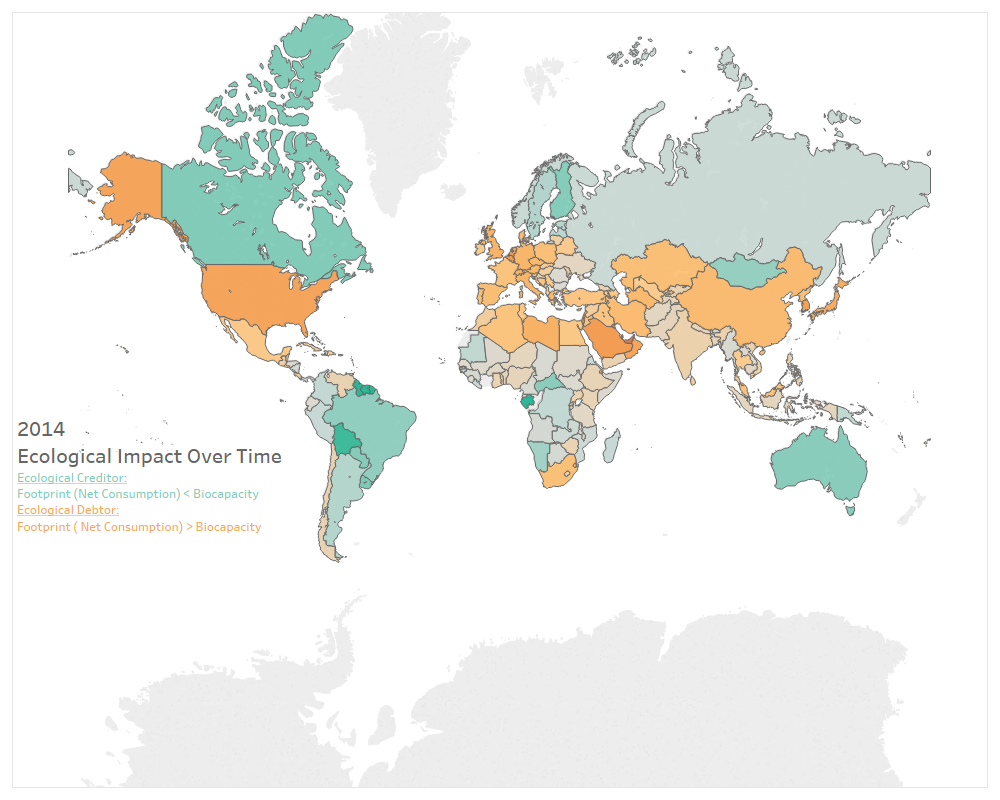
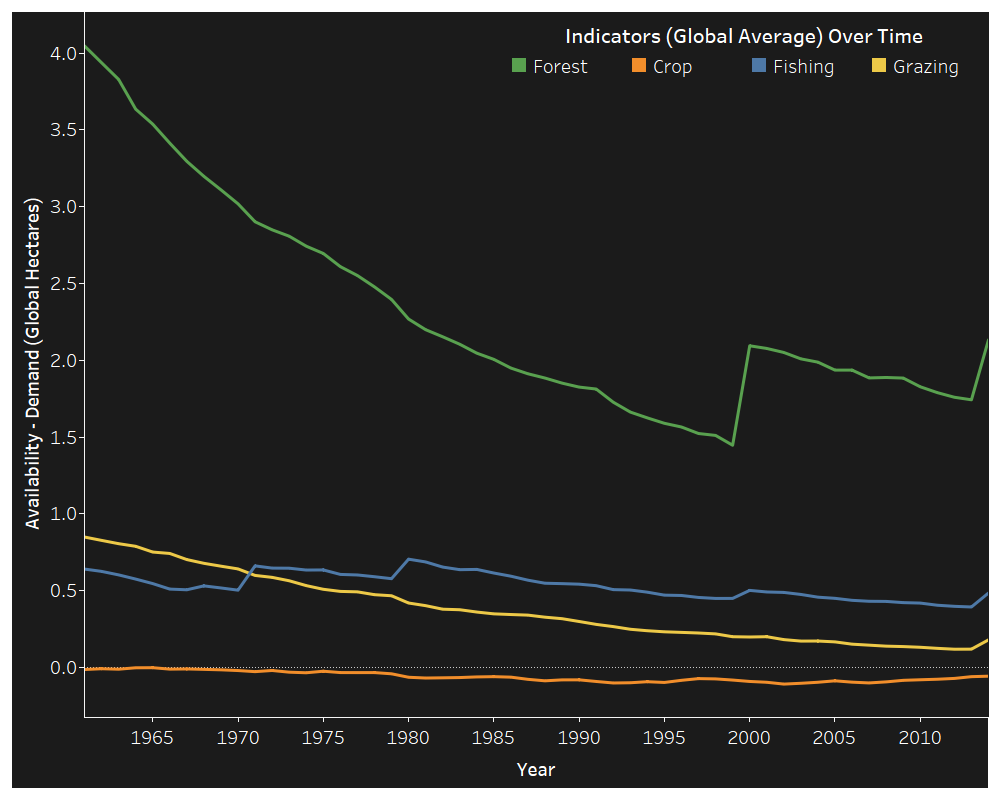
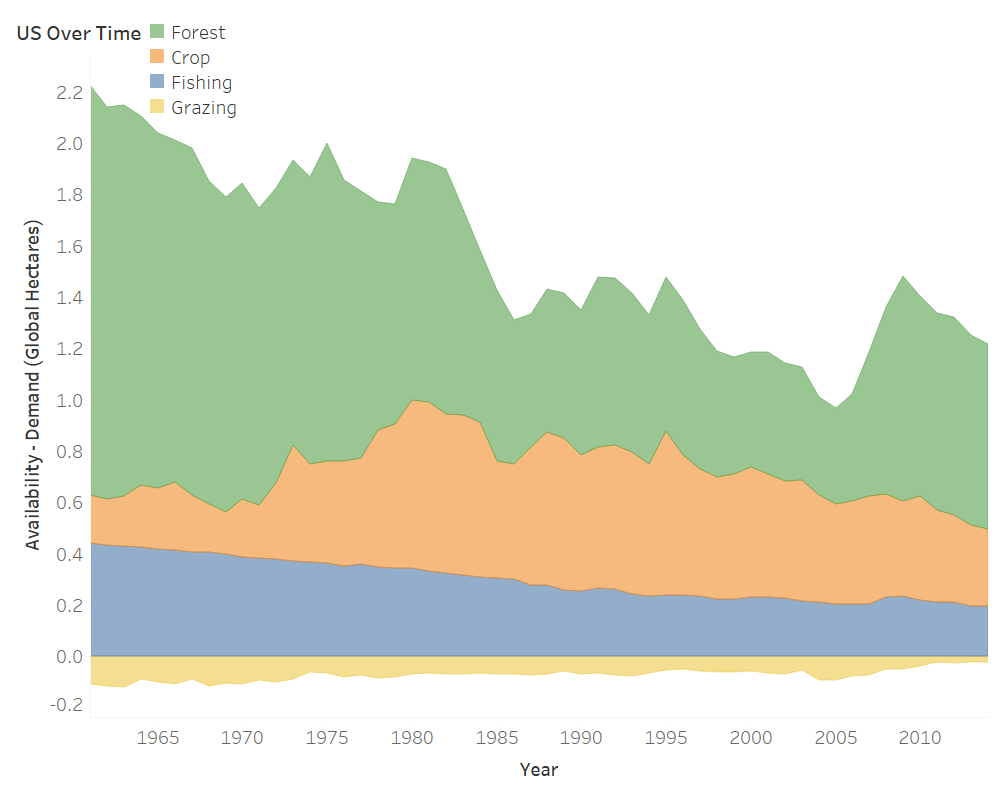
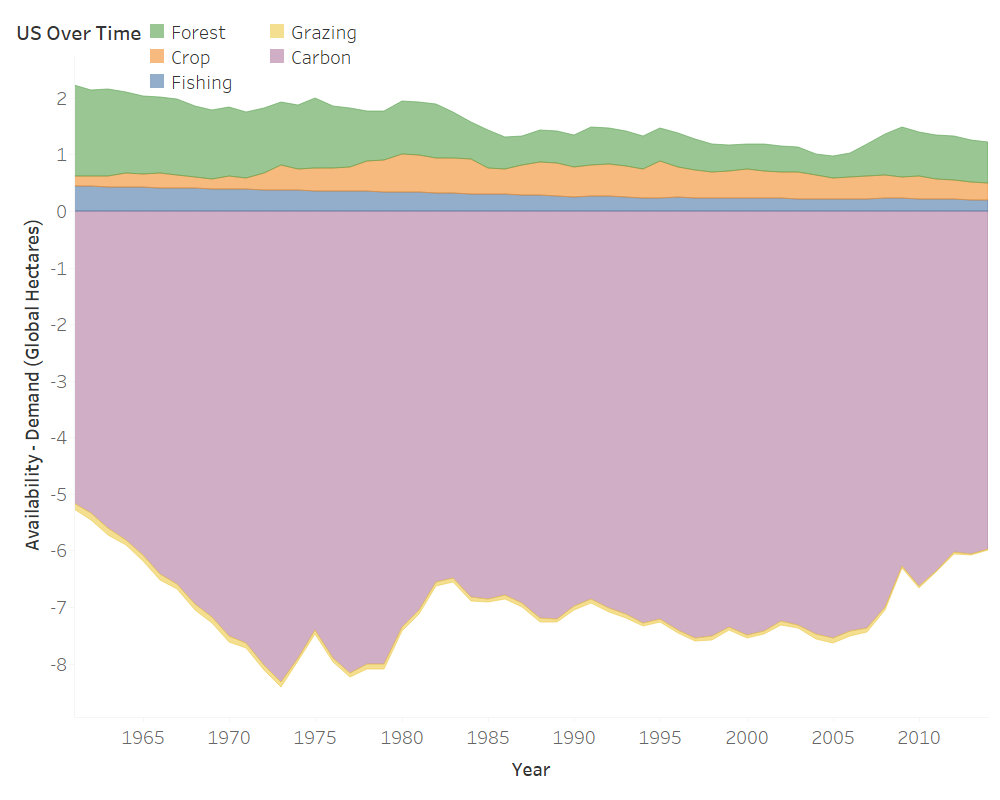
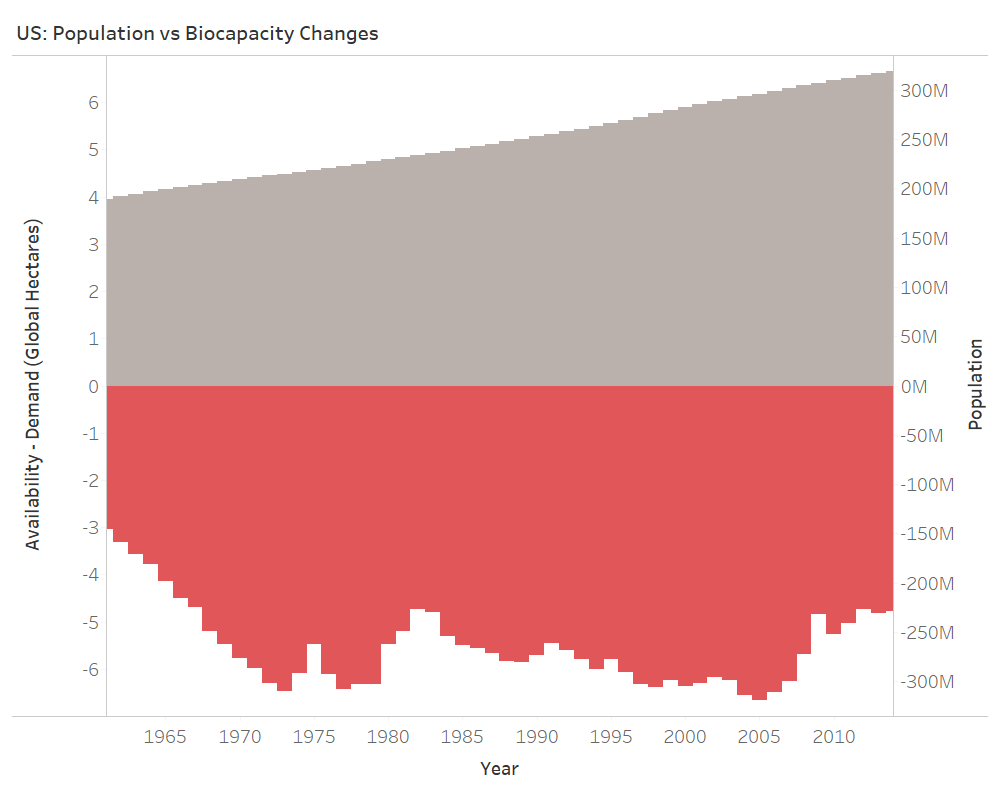 The US population has been growing at a linear pace since 1961. Changes in consumption have been more sporadic. Intuitively, population plays a role in in how much a country consumes. The variability in the plot of consumption, however, indicates more of an interaction between population and growth of consumption and any other number of variables not included in the data-set: policy, economic prosperity, war, etc. This being said, let’s take a look at GDP.
The US population has been growing at a linear pace since 1961. Changes in consumption have been more sporadic. Intuitively, population plays a role in in how much a country consumes. The variability in the plot of consumption, however, indicates more of an interaction between population and growth of consumption and any other number of variables not included in the data-set: policy, economic prosperity, war, etc. This being said, let’s take a look at GDP.










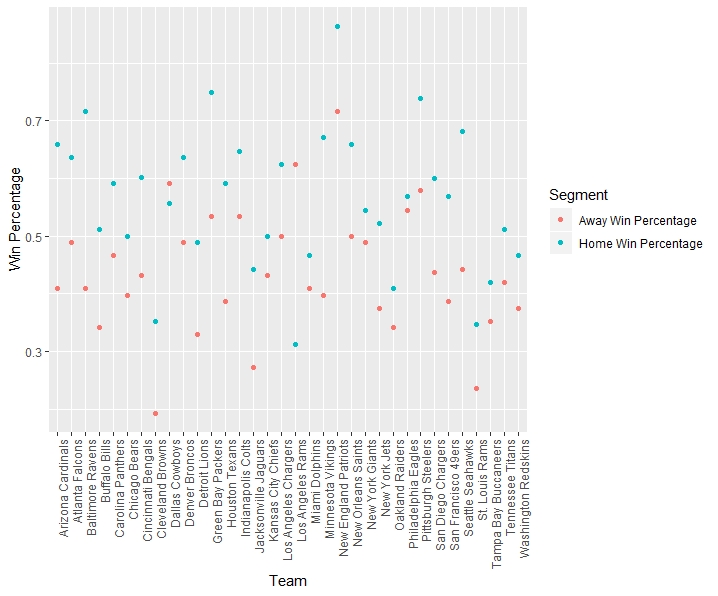 As it can be seen, the win percentage of games played at home tends to be higher than the win percentage of games played as a visiting team. Out of all of the teams over this 11 year period, there are only two teams where this does not hold: the Dallas Cowboys and Los Angeles Rams. The LA Rams have a much smaller sample size, due to their move in 2016, causing unsurprising variability from the norm. But, for Dallas, how can you claim to be America’s team when you aren’t even Texas’ team?…
As it can be seen, the win percentage of games played at home tends to be higher than the win percentage of games played as a visiting team. Out of all of the teams over this 11 year period, there are only two teams where this does not hold: the Dallas Cowboys and Los Angeles Rams. The LA Rams have a much smaller sample size, due to their move in 2016, causing unsurprising variability from the norm. But, for Dallas, how can you claim to be America’s team when you aren’t even Texas’ team?…















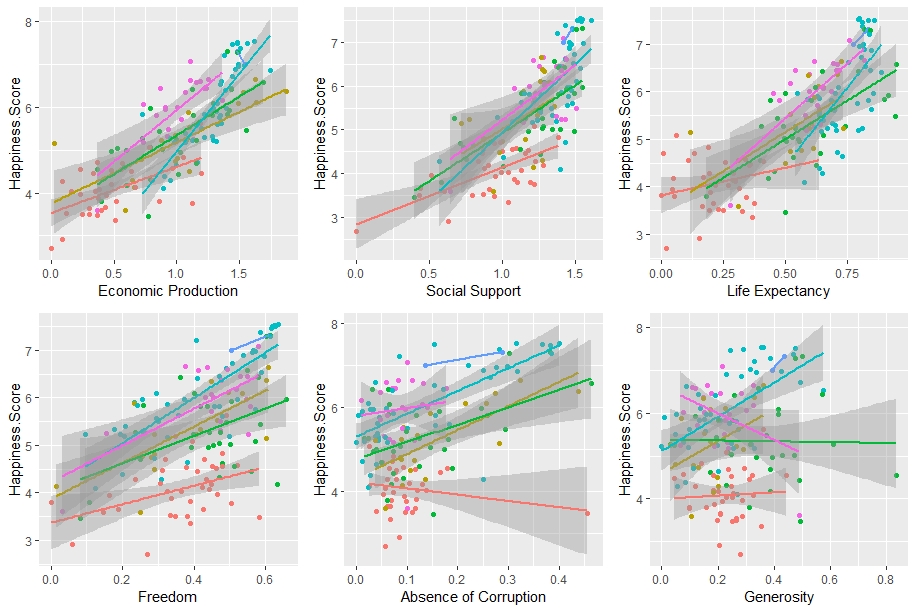
 These graphs show each of the 6 major factors graphed against happiness scores for each country, colored based on the region in which they reside. The trend lines show a rough relationship between these variables, based on region. What trends and relationships do you begin to see?
These graphs show each of the 6 major factors graphed against happiness scores for each country, colored based on the region in which they reside. The trend lines show a rough relationship between these variables, based on region. What trends and relationships do you begin to see?